Modern Cloud Architecture For Global Teams
In alignment with our strategic objective to enable technical leadership to architect high-performance, low-latency global systems, this release addresses the "geography tax" inherent in legacy hub-and-spoke models. Drawing from the Content Nucleus, this capability marks a shift toward a unified global operating environment where infrastructure performance is decoupled from physical location.
What’s New
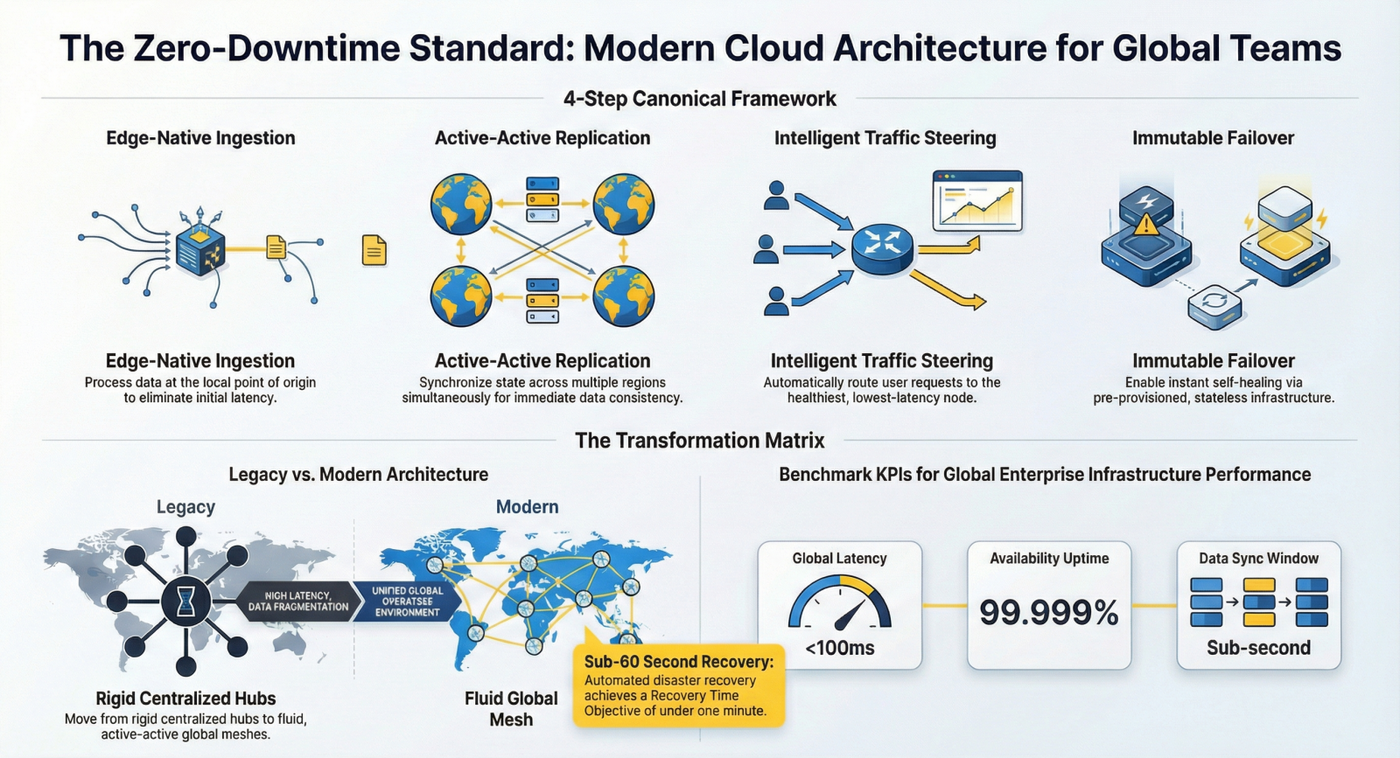
We are introducing a standardized transition path from rigid, centralized architectures to a fluid "Global Mesh" model. This capability allows for the deployment of an Enterprise Global Cloud Architecture that supports distributed teams with zero perceived lag and near-real-time data synchronization.
Why It Matters
This transition is designed to eliminate productivity bottlenecks caused by data fragmentation and regional downtime. By adopting these standards, enterprises can achieve the following verified outcomes from our KPI Matrix:
- Global Latency Reduction: Maintaining a target of <100ms globally.
- Availability Uptime: Achieving a standard of 99.999%.
- Data Consistency Window: Ensuring a sub-second synchronization across all active regions.
- Failover RTO: Reducing the Recovery Time Objective to less than 60 seconds.
Who It’s For
This release is specifically engineered for CTOs and VPs of Infrastructure responsible for the performance and resilience of global mission-critical systems. It provides the architectural blueprint necessary to support high-volume transaction integrity in the US and navigate the geographic complexities of the APAC region.
How It Works
The capability is delivered through a four-step Canonical Framework that ensures infrastructure remains a velocity driver rather than a bottleneck:
- Edge-Native Ingestion: Local processing of data at the point of origin to remove initial latency.
- Active-Active Replication: Simultaneous state synchronization across multiple regions for immediate consistency.
- Intelligent Traffic Steering: Automated routing of user requests to the healthiest, lowest-latency node.
- Immutable Failover: Use of pre-provisioned, stateless infrastructure for automated self-healing and rapid recovery.